企业级的邮件群发软件,采用VC++开发,严格按照Windows应用程序和多线程标准编写,程序运行稳定性远远高于同类程序。按照最易使用的原则开发,Windows典型界面,操作最为易用,操作方便,最高线程为1000,目前没有任何一款群发软件可超过她!·多线程特快专递与SMTP服务器转发双重发送,并可自动切换;·采用Postfix标准,轻松突破FoxMail,QQ邮件等过滤方式;·独家采用邮件分类发送,轻松防止163,126等多线程检测;·独特的反Anti-spam和动态域名技术大大提高发送成功率;·支持失败后自动重发,并可自定重发次数(仅数据库版支持)·支持HTML和文本自动切换格式邮件;·邮件支持不同地区编码(简体、繁体、韩文、西欧、日文等);·多附件添加功能,一次可发送多个附件;·可要求收件人发送邮件收条,反馈邮件接收状况;·动态显示邮件发送状态提供详细的发送记录;·发件人、邮箱等可自动随机产生;·内嵌百家姓,可自动产生中文姓名;·智能化的发送完自动关机,自动断开拨号连接功能;·附带Internet域名注册查询、域名到IP查询,和IP地址到国家地区的查询;·超大邮件发送,大到100亿个邮件,不受限制;·内置1000个线程可选择,发送速度无人能敌;。
·网上在线升级和新版本自动提示;·支持Outlook邮件EML、MSG格式导入;·邮件退订,可以控制某些邮件或服务器的邮件不发送,防止产生垃圾邮件;·友好模式可在邮件中插入8个变量,比如变量%RECEIVER%为接收人等等;·直接从任何数据库(Access,SQL,Oracle,Sybase)导入任何字段并替换到邮件中;·实时保存发送结果,防止意外后不能保存结果;·导入Outlook地址簿,方便将地址簿共享·定时自动拨号连接,更新IP,防止ISP屏蔽;·内置大容量域名Cache,减少网络数据交换,防止DNS屏蔽;·多线程实时调节功能,非常方便。 ·支持多SMTP发送功能和批量匿名SMTP导入; ·支持SOCK5,SOCK4,HTTP代理;·互联网时间校对,和原子钟时间同步;·断点传送,重新开启程序即可自动接着上次继续发送;·程序智能报错,更新更快。注意::软件的效验厉害,放在他目录的补丁每次就有一次运行机会,如果再用请将压缩包里的补丁重新放在软件目录运行就可以:)
原正式版下载:
菏泽网通-菏泽信息港
内蒙古网通[本地下载]
四川网通 [本地下载]
哈尔滨信息港[本地下载]
河南网通-景安数据中心
济源网通 [本地下载]
烟台热线 [本地下载]
辽宁网通-北方数据中心
大连信息港 [本地下载]
临汾网通 [本地下载]
德州网通 - 鲁北热线
广州网通 [本地下载]
破解下载:
http://www.gigasize.com/get.php/-1100134752/VolleyMail_8.8_key.rar
2007/06/12
VolleyMail邮件群发专家 8.82 正式版 破解补丁
2007/06/08
微软发布官方提升关机速度程序
解决Windows 2000\\NT\\XP\\Windows Server 2003关机速度慢的问题
http://download.microsoft.com/download/a/8/7/a87b3d05-cd04-4743-a23b-b16645e075ac/UPHClean-Setup.msi
2007/06/07
在线代理突破封锁,上被封的站点必备!
使用www.9i7.cn在线代理站的代理功能,就可以使您上网无痕,本可以迅速登陆你要去的国外站点实现加速网络的功能:)。不过您的网速也要够快啊。
the ultimate blogger template list
2girlsdesign
Anti-Ivy Linkware and Shareware Blog Templates
Bejewelled
Blog-Plates
BlogDesigns
Blog Fashions
Blogger Templates
BlogSkins
Blog Templates @ ehsany.com - includes templates in Farsi
Colorized Pixels
CSS Colouring Book
Elated Page Kits
Eris Weblog Template Generator (multiple software support)
EyeForBeauty - Templates for your Journal
EyeSites
glish.com - Blogger Template
Groovy Lizard
Joyful Heart Designs
Karysima Pre-coded Movable Type Templates
Love Productions Blogplates
noipo
Point of Focus - Blogger templates
shellen.com - Blogger Templates
Spiderman 2 Blog Templates
Starlit Dreams Weblog Designs
Weblogger Themes
orkut
Orkut是Google公司推出的社会性网络服务。通过这一服务,用户可以在互联网上建立一个虚拟社会关系网。
拥有Orkut帐户,必须首先成为Gmail帐户。目前已经开放注册。
Google打算让Gmail作为使用Google一些了服务的通用帐户,在Orkut,默认的登陆密码也是Gmail帐户的用户名和密码。一旦Orkut帐户和Gmail帐户捆绑以后,Orkut的登陆用户名和密码就不在出现。这一点类似于网易或者搜狐和微软MSN的通行证。
https://www.orkut.com/
windows正版验证(盜版系统变正版)
windows盗版提示
下载好后先装VBj脚本,然后在安装msWGA.
弄好之后软件会直接提示你去微软认证
下载:http://www.duote.net/3577037328E0C02C(请勿用软件打开)
http://www.weifengyi.cn/article.asp?id=163
2007/06/06
日本的交通
日本的交通便捷,以新干线为代表的铁路交通网纵贯全国。新干线始建于20世纪六十年代,由于其快速、安全和舒适,因此深受人们的喜爱,是远行的首选工具。东京和大阪相距556.4公里,新干线的开通把普通列车九个小时的车程一下子缩短到两个半小时左右,极大地方便了商务出差和旅游的需要。
東京車站月台上的新幹線300與700系車頭 / 维基百科
日本的私家车非常普遍,尤其在农村,几乎是家家拥有,是出行的主要交通工具。而在像东京这样的大城市,由于道路狭窄,交通拥挤,所以私家车多数只用于假日旅游,而非日常的上下班。
在东京上下班主要利用JR电车、私铁电车和地铁。电车和地铁交通网纵横交错,线路众多,覆盖整个关东地区。电车和地铁都有准确的时刻表,车辆绝对的准时准点。如果事先在互联网上查询,只要输入出发地和目的地,就可查清乘换的线路、到达时间,以及票价,而绝不会担心迟到。在电车和地铁车站的售票处和站台都张贴着线路乘换图,而且乘换标志非常清晰、一目了然。在东京的主要电车和地铁站除了日文标志以外,在二〇〇二年日韩足球世界杯开赛之际,还新设了中、英、韩等三种语言标记,这样就大大地方便了初到东京的外国人乘车。
不论是电车还是地铁,进站时都是以自动检票机为主,而且最近被称为SUICA或是PASMO的非接触型的磁卡逐渐普及,只要事先在磁卡中输入一定的金额,进站和出站时只要在自动检票机上轻轻一晃,检票机就会自动收取所需的票额。而且电车、地铁和公共汽车都可使用或PASMO。
东京的公共汽车,利用的人相对较少。公共汽车也有时刻表。但由于高峰时的道路堵塞,有时会出现延误。
日本的交通
日本的交通便捷,以新干线为代表的铁路交通网纵贯全国。新干线始建于20世纪六十年代,由于其快速、安全和舒适,因此深受人们的喜爱,是远行的首选工具。东京和大阪相距556.4公里,新干线的开通把普通列车九个小时的车程一下子缩短到两个半小时左右,极大地方便了商务出差和旅游的需要。
東京車站月台上的新幹線300與700系車頭 / 维基百科
日本的私家车非常普遍,尤其在农村,几乎是家家拥有,是出行的主要交通工具。而在像东京这样的大城市,由于道路狭窄,交通拥挤,所以私家车多数只用于假日旅游,而非日常的上下班。
在东京上下班主要利用JR电车、私铁电车和地铁。电车和地铁交通网纵横交错,线路众多,覆盖整个关东地区。电车和地铁都有准确的时刻表,车辆绝对的准时准点。如果事先在互联网上查询,只要输入出发地和目的地,就可查清乘换的线路、到达时间,以及票价,而绝不会担心迟到。在电车和地铁车站的售票处和站台都张贴着线路乘换图,而且乘换标志非常清晰、一目了然。在东京的主要电车和地铁站除了日文标志以外,在二〇〇二年日韩足球世界杯开赛之际,还新设了中、英、韩等三种语言标记,这样就大大地方便了初到东京的外国人乘车。
不论是电车还是地铁,进站时都是以自动检票机为主,而且最近被称为SUICA或是PASMO的非接触型的磁卡逐渐普及,只要事先在磁卡中输入一定的金额,进站和出站时只要在自动检票机上轻轻一晃,检票机就会自动收取所需的票额。而且电车、地铁和公共汽车都可使用或PASMO。
东京的公共汽车,利用的人相对较少。公共汽车也有时刻表。但由于高峰时的道路堵塞,有时会出现延误。
日本的扶轮国际俱乐部
扶轮国际俱乐部(Rotary Club)是一个主要以提倡通过提高职业道德标准从而实现职业奉献进而向社会提供博爱的奉献以及促进国际间的相互了解,和平为目的的组织。日本的扶轮俱乐部最早成立于1920年,现在全日本大约有2300个扶轮俱乐部以及超过10万的成员。
作为国际奉献以及促进国际间交流的一环,日本的财团法人扶轮社米山奖学会向一部分的在日外国留学生提供较为高额的奖学金以助其完成学业。笔者有幸得到扶轮社米山奖学会的帮助得以顺利地按时完成了博士课程的学业。
在通过考试正式成为米山奖学生后,根据奖学生所在的地区,扶轮社米山奖学会就会指定一个扶轮俱乐部并由2名该俱乐部的成员负责照顾该奖学生。扶轮俱乐部每周召开一次例会,奖学生每月参加一次例会,每月的奖学金在例会时交给该奖学生(主要目的是让奖学生参加例会从而亲身体验俱乐部成员的奉献精神)。笔者所在的俱乐部每周四举行例会,由各个委员汇报上周各方面的社会奉献业绩,对俱乐部成员在其事业方面所取得的成就进行表彰, 同时会邀请一位其他扶轮俱乐部的成员或一般人士到该俱乐部,作为讲师结合自己的职业或亲身体验过的事情,进行约40分钟的讲演。讲演的题目从如何制造焰火到器官移植等等可谓五花八门,但内容都是如何通过自己的职业进行社会奉献。在例会结束后一般都有大约1小时左右的欢谈时间,成员们会利用这段时间交流活动经验。为了促进国际间的相互理解,俱乐部不仅为在日的外国留学生提供奖学金,同时也积极地提供奖学金支持日本国内的学生到海外留学。留学的内容既有学术方面的,也有文化方面的。如我所在的俱乐部所支援的日本留学生中,有一个学生在荷兰学习做木鞋,另一个学生在保加利亚学习做酸奶,正是通过留学生们在各方面的留学,从而促进了各种各样文化之间的交流以及国际间的相互了解。
笔者虽然每月只参加了一次例会,但是就是这短短的每月一次的例会也足以使笔者深深地感到了俱乐部成员那种博爱的奉献精神,并在时间允许的情况下和俱乐部成员们一起多次参加了社会奉献活动,如义务献血活动等。笔者虽然已经离开曾经所在的扶轮俱乐部多年,但至今仍然保持着和俱乐部成员们频繁的书信往来,并在可能的情况下提供自己的一点微薄之力。
国际扶轮社
国际扶轮社是一个组织扶轮社(服务社)遍布世界(32000多名俱乐部,在200多个国家和地区)和1.2万人在世界各地. The members of Rotary Clubs are known as Rotarians .成员扶轮社是著名的扶轮社员. Rotary was the first established service organization and is currently the largest in the world.扶轮社是最早成立的服务组织,是目前世界上最大的. It was also the first organization of any kind that did not use religion as a test of membership.这也是首次组织任何形式的,不利用宗教作为一个测试的成员. The stated purpose of the group is to bring together business and professional leaders who provide humanitarian service, encourage high ethical standards in all vocations, and help build goodwill and peace in the world.溜滑梯集团,是汇集商业及专业的领导者,提供人道主义服务,鼓励高道德标准,在所有职业中,有利于建立友好和世界和平作出贡献. Members meet weekly for breakfast, lunch or dinner, which is a social event as well as a time to organize work on their service goals.成员每周开会一次早餐,午餐或晚餐,这是一个社会事件以及时间来筹办工作,对他们的服务目标.
Their best-known motto is "Service above Self."其最有名的格言是"服务超过自我" Another motto is "They profit most who serve best".另一个口号是"获取利润,大部分的人最好的服务". [1] The resolution to remove gender specific terminology from secondary motto was taken by Rotary International Council of Legislation in 2004.[1]该决议以消除性别特定的术语中的座右铭是由国际扶轮社理事会法例于2004年完成href="http://www।rotary.org/">http://www।rotary.org/
日本社会现象_网吧难民
今年3月份开始,日本各大报纸上出现了对于网吧难民问题的连篇报道。网吧难民指的是一部分靠打零工为生的年轻人,因为没钱租房,晚上在网吧过夜的现象。和流浪人员相比,他们虽不至于露宿街头,但这种贫困层的日益低龄化问题引起了社会极大的关注。
社会言论的多数均将这种现象的产生归咎于日本企业雇用环境的不断恶化,尤其是处于残酷价格竞争中的企业为了削减人工费剥夺了很多年轻人成为正式公司职员的机会。成为网吧难民,最直接的原因就是他们的收入无法维系他们在外面租房的费用。其中,固然有社会的原因,但我认为更多的是他们自身的问题。各种报道过于将责任转嫁到社会,而少有追究其个人的原因。
试想日本众多的留学生,既要维系生活开销,还要交纳学费。论语言,很多人是到日本才开始学习日语的。论时间,留学生既要学习,还要打工。论年龄,30多岁的留学生不在少数,很多人甚至还有家庭有小孩。在找工作的难度上,留学生也要远远大于日本的年轻人。但即使这样,也很少听说留学生中出现过网吧难民。我一直认为在日本靠打工维系自己的生活,并不是非常困难的事情,关键是“事在人为”。
“逆水行舟,不进则退”。水的流向是人不能随便左右的,但舟的进退却往往取决于自己。
Altova XMLSpy 2006 汉化版(简体中文安装破解版)
XMLSpy是所有XML编辑器中做得非常好的一个软件,支持WYSWYG。支持Unicode、多字符集,支持Well-formed和Validated两种类型的XML文档,支持NewsML等多种标准XML文档的所见即所得的编辑,同时提供了强有力的样式表设计。本版增加了几个很有用的功能:XSLT 调试工具,XSL 也就是所谓的扩展风格表单语言(Extensible Stylesheet Language)由3种语言组成。这三种语言负责把XML文档转换为其他格式。XML FO (XSL格式化对象:XSL Formatting Objects)说明可视的文档格式化,而 Xpath 则访问XML文档的特定部分。而 XSLT(XSL Transformations)就是把某一XML文档转换为其他格式的实际语言。 更多情况,WSDL 编辑器, WSDL就是描述XML Web服务的标准XML格式,WSDL由Ariba、Intel、IBM和微软等开发商提出。它用一种和具体语言无关的抽象方式定义了给定Web服务收发的有关操作和消息。Java / C++ 代码生成器,这个可以从 XML Schemas 文档中生成 Java/C++ 代码。 集成 Tamino, Tamino 产品是世界第一套以纯粹且标准的XML格式进行资料储存于抓取的信息服务器,一个能够将企业资料转换为Internet物件,提供资料交换和应用程序集成环境同时又支持WEB的完整资料管理系统。这里下载
>>>Read More...lds 词典转换器
内核编译链接过程是依靠vmlinux.lds文件,以arm为例vmlinux.lds文件位于kernel/arch/arm/vmlinux.lds,但是该文件是由vmlinux-armv.lds.in生成的,根据编译选项的不同源文件还可以是vmlinux-armo.lds.in,vmlinux-armv-xip.lds.in。
vmlinux-armv.lds的生成过程在kernel/arch/arm/Makefile中
LDSCRIPT = arch/arm/vmlinux-armv.lds.in
arch/arm/vmlinux.lds: arch/arm/Makefile $(LDSCRIPT) \ $(wildcard include/config/cpu/32.h) \ $(wildcard include/config/cpu/26.h) \ $(wildcard include/config/arch/*.h) @echo ' Generating mailto:$@ @sed 's/TEXTADDR/$(TEXTADDR)/;s/DATAADDR/$(DATAADDR)/' $(LDSCRIPT) >$@
vmlinux-armv.lds.in文件的内容:
OUTPUT_ARCH(arm)ENTRY(stext)SECTIONS{ . = TEXTADDR; .init : { /* Init code and data */ _stext = .; __init_begin = .; *(.text.init) __proc_info_begin = .; *(.proc.info) __proc_info_end = .; __arch_info_begin = .; *(.arch.info) __arch_info_end = .; __tagtable_begin = .; *(.taglist) __tagtable_end = .; *(.data.init) . = ALIGN(16); __setup_start = .; *(.setup.init) __setup_end = .; __initcall_start = .; *(.initcall.init) __initcall_end = .; . = ALIGN(4096); __init_end = .; } 其中TEXTADDR就是内核启动的虚拟地址,定义在kernel/arch/arm/Makefile中:ifeq ($(CONFIG_CPU_32),y)PROCESSOR = armvTEXTADDR = 0xC0008000LDSCRIPT = arch/arm/vmlinux-armv.lds.inendif需要注意的是这里是虚拟地址而不是物理地址。
一般情况下都在生成vmlinux后,再对内核进行压缩成为zImage,压缩的目录是kernel/arch/arm/boot。下载到flash中的是压缩后的zImage文件,zImage是由压缩后的vmlinux和解压缩程序组成,如下图所示:
-----------------\ ----------------- \ \ decompress code vmlinux \ ----------------- zImage \ /----------------- / / / -----------------/ zImage链接脚本也叫做vmlinux.lds,位于kernel/arch/arm/boot/compressed。是由同一目录下的vmlinux.lds.in文件生成的,内容如下:OUTPUT_ARCH(arm)ENTRY(_start)SECTIONS { . = LOAD_ADDR; _load_addr = .; . = TEXT_START; _text = .; .text : { _start = .; 其中LOAD_ADDR就是zImage中解压缩代码的ram偏移地址,TEXT_START是内核ram启动的偏移地址,这个地址是物理地址。在kernel/arch/arm/boot/Makefile文件中定义了:ZTEXTADDR =0ZRELADDR = 0xa0008000
ZTEXTADDR就是解压缩代码的ram偏移地址,ZRELADDR是内核ram启动的偏移地址,这里看到指定ZTEXTADDR的地址为0,明显是不正确的,因为我的平台上的ram起始地址是0xa0000000,在Makefile文件中看到了对该地址设置的几行注释:# We now have a PIC decompressor implementation. Decompressors running# from RAM should not define ZTEXTADDR. Decompressors running directly# from ROM or Flash must define ZTEXTADDR (preferably via the config)他的意识是如果是在ram中进行解压缩时,不用指定它在ram中的运行地址,如果是在flash中就必须指定他的地址。所以这里将ZTEXTADDR指定为0,也就是没有真正指定地址。
在kernel/arch/arm/boot/compressed/Makefile文件有一行脚本:SEDFLAGS = s/TEXT_START/$(ZTEXTADDR)/;s/LOAD_ADDR/$(ZRELADDR)/;s/BSS_START/$(ZBSSADDR)/使得TEXT_START = ZTEXTADDR,LOAD_ADDR = ZRELADDR。
这样vmlinux।lds的生成过程如下:vmlinux.lds: vmlinux.lds.in Makefile $(TOPDIR)/arch/$(ARCH)/boot/Makefile $(TOPDIR)/.config @sed "$(SEDFLAGS)" <> $@ 以上就是我对内核启动地址的分析,总结一下内核启动地址的设置:1、设置kernel/arch/arm/Makefile文件中的 TEXTADDR = 0xC0008000 内核启动的虚拟地址2、设置kernel/arch/arm/boot/Makefile文件中的 ZRELADDR = 0xa0008000 内核启动的物理地址 如果需要从flash中启动还需要设置 ZTEXTADDR地址。
下载词典编辑器:
http://hi.baidu.com/cgshare/blog/item/60e68609a99632256a60fb95.html
2007/06/05
2007/06/04

Flash игра Get the Glass

Flash игра сделанная на подобии старых игр с кубиком. Кидаем кубик и продвигаемся на выпавшее количество клеток, а за тобой гонится милиция. Обалденная графика и геймплей, всё сделано очень качественно, очень советую посмотреть, единственное что без знания английского играть будет сложновато.
>>>Read More...
Создание Flash сайтов
Дискуссия о месте технологии Flash в волшебном мире Интернет велись с момента появления технологии, и были даже не дискуссиями а скорее постоянным нытьем о том, что flash противоречит usability (в понимании традиционного user experience пользователя броузера как интерфейса взаимодействия с веб-контентом), с одной стороны - и растущим количеством Flash сайтов с другой. Flash мог все больше и больше, и требования его противников сменялись с "верните нам кнопку Back" на "Проиндекструйте флеш-сайт", потом на "Сделайте флеш-сайт динамическим", потом на "Где поиск?" - и так далее, или же все одновременно. Все эти пожелания, как и многое другое, составили на данный момент некую догматику требований к современному флеш-сайту - не зафиксированную в документациях и стандартах, но в то же время довольно четкую и универсальную. Возможно, изначальная цель этих требований - максимально приблизить флеш-сайт, как интерфейс и как приложение, к html сайту - и потеряла актуальность, но сам подход, делающий флеш-сайт понятным, удобным, легким в использовании как посетителем, так и владельцем, надежным и интегрированым в html и серверное окружение - стал для создателей флеш-сайтов тем, от чего принято отталкиваться.
Поэтому я бы хотел уделить внимание некоторым деталям этого подхода, которые будет полезно узнать человеку, который создает флеш-сайты. Поскольку я буду попутно приводить объяснения - как именно реализовать то или другое из описанного - видимо, этот текст будет интересен флеш-разработчикам в большей степени, чем кому либо другому.
Первое о чем хотелось бы поговорить - структура сайта. Глобально сайт (как флеш, так и любой другой)представляет собой некий набор единиц иформации (страницы), связанных между собой ссылками(навигация). Это - тот постулат, от которого мы будем отталкиваться. Поскольку 99 процентов интерактивности на нашем "идеальном сайте" составляет переход от одной единицы информации к другой - очевидно, что от того, как организованы связи между этими страницами зависит очень многое - а именно, возможность или невозможность реализовать тот или иной функционал. Попытки построить логику работы сайта, отталкиваясь от размышлений вида "вот мы зашли на первую страницу/открыли первый уровень главного меню/оказались на странице 'о нас' --- и теперь мы должны отсюда смочь выйти на страницу продукции - поэтому мы тут поставим ссылку" - обычно приводят к созданию html - сайтов с путаной навигацией, что плохо, но не смертельно - потому что в html сайте всегда можно поставить эту злополучную ссылку, потом еще 10 ссылок в разных местах - и будет работать.
При создании сайтов на flash такой подход приводит к гораздо более печальным последствиям - мы оказались на странице "о нас", а ссылку на страницу, где помещена история разработки нашего логотипа (разел "работы"/ подраздел "работы для себя - любимых"/ выбор-из-выпадающего-списка "логотипы") - мы поставить не можем, потому, что перед разделом "работы" у нас проигрывается анимация поднимающегося занавеса, после этого выползает боковое меню с клиентами (да - еще надо не забыть убить автивность кнопок главного меню и запустить звук фанфар), опять же этот выпадающий список надо открыть на нужном пункте - в общем, хаос приходит в гости и прочно обустраивается в скрипте (в котором появляется десяток новых условий), дизайне (который мы быстро лишаем поднимающегося занавеса) и голове, которая готовится к коллапсу мозга. Как всего этого избежать и что надо сделать чтобы мы были готовы к любым, самым неожиданным поворотам в структуре контента?
Ответ - присваивание каждой единице информации своего пути, создание центральной системы навигации, и завязка всего интерактива на неё. Мы не будем заниматься флеш-извращениями вроде создания динамической навигации бесконечной вложенности и применения нашего подхода к ней - не потому, что это гипер-сложно, а потому, что это не имеет отношения к 99 процентам конкретных задач, которые встают перед разработчиком сайта.
Обратимся к реальности - некая фирма заказывает сайт, с неким количеством уровней структуры информации - пусть этих уровней будет три, чтобы нам было проще - главные страницы [банальные "о нас", "услуги", "продукция", "контакты"], вложенные страницы первого уровня ["бетонные плиты", "кованое железо", "бочки"] и второго уровня ["бочки круглые", "квадратные" "тругольные"]. Раскидав все имеющиеся страницы примерно равномерно по обозримому пространству нашего воображения, мы видим, что не все так просто, как кажется - навигация не получается такой же прямолинейной, как на схеме - (от более крупного к менее крупному и обратно): из "круглых бочек" нам понадобится ссылка на список клиентов, отуда, в свою очередь - на продукцию для конкретного заказчика - и так далее. И это только то, что заказчик написал в ТЗ - вполне вероятно, что за неделю до сдачи проекта, он захочет на КАЖДЫЙ продукт повесить ссылки на ВСЕ продукты для клиента, которые заказал этот продукт. Поэтому правильным подходом будет изначальное обеспечение возможности из любой страницы перейти на любую другую.
Так как у нас 3 уровня вложенности - прикидываем дефолтное расположение страниц - и присваиваем каждой переменную вида "1/2/3" - где 1 - это индекс одной из главных страниц, 2 - индекс вложенной страницы первого уровня, с которой мы попали на текущую - которая и есть номер 3. Проще всего присваивать эти переменные прямо при построении главной навигации. Это просто, но это только 10 процентов от того, чо нам предстоит сделать. Если мы хотим без проблем перейти со страницы "2/5/12" на страницу "4/1/2", нам надо создать такой механизм навигации, который будет считывать текущий путь, в обратной очередности проиводть сопутствующие навигации действия - открывание вложенных меню, анимацию появления страниц и так далее - а затем делать все тоже самое с "нуля" - пока мы не окажемся на странице, которую мы хотим открыть. Каждое действие пользователя должно проходить такой путь - даже если он переходит с одной товара на другой внутри одной страницы одного раздела - в этом случае система должна принимать, но игнорировать те участки искомого пути, которые идентичны текущему - т.е уже открыты. Как именно построить такой механизм я рассказывать не буду - это долго, беспредметно, сугубо профессионально и неуниверсально. Универсальность заканчивается на принципах: отрывать действия от событий, чтобы их можно было вызвать в любой момент, строить и оптимизировать конвееры исполняемых операций, которым можно будет посылать список требующих поочередного выполнения действий, следить, чтобы все это не тормозило - а именно, не запускать одновременно ВСЁ, что можно - на то у нас и существуют пути, чтобы спокойно по очереди все открыть-закрыть. Дальше идет область применения вашей фантазии.
Построив навигацию по такому принципу, мы получаем несколько очень важных преимуществ:
- во-первых, мы можем в любой момент в любом месте сайта повесить ссылку на любое другое место - нам достаточно будет просто послать в функцию, осуществляющую контроль над открытием и закрытием уровней искомый путь "a/b/c"
-во-вторых, мы можем легко привязать сайту дополнительный функционал - допустим, поиск: послав запрос на сервер по keywords нам достаточно будет разбить полученный xml, состоящий из путей вида "1/2/3" (который также легко генерится ), быстренько выстроить в ряд кнопки и присвоить каждой - нужный путь.
Поиск - еще одна важная деталь, присутствие которой на флеш-сайте во многом смягчает критику посетителей по поводу его usability и позвляет посетителем расслабиться и получать удовольствие от летающих звезд, видео-плейбеков, потрясающих пружинящих контакт-форм и прочих прелестей, которые нам предоставляет flash.
-в-третьих, мы можем - также без особых усилий - привязать наш сайт к навигации броузера - кнопкам back и forward например. Описание механизма работы perma links можно найти на сайте flashguru.co.uk - так показан пример из страницы с двумя фреймами - в кратце принцип таков: основной swf лежит в одном фрейме, вспомогательный - в другом. При навигации первый посылает некую переменную, соответствующую искомой странице на php-скрипт, который перегружает фрейм с вспомогательным swf - присваивая ему параметром эту переменную - после чего вспомогательный swf по local connection передает эту переменную обратно в главный - и тот осуществляет переход на следующую страницу. Таким образом мы получаем document.history со всеми посещенными страницами сайта - и можем соответственно пользоваться навигацией back и forward для перемещения по нему. Надо ли говорить, что если мы строим сайт по схеме, предложеной выше - то нам понадобится лишь пропустить нашу систему навигации еще одним звеном через local connection - чтобы все наши "a/b/c" записыавлись в историю броузера. И не надо мне рассказывать, что это ненажедно, медленно, муторно итд - я делал это много раз и знаю, о чем говорю. Тем более, что интеграция с навигацией броузера - одно из тех негласных требований к современному флеш-сайту, о которых я говорил в самом начале.
-в-четвертых, сам факт того, что мы всегда знаем - где находится пользователь - и можем при желании сообщить об этом - а также проследить его путь по сайту - не может не радовать и не успокаивать. Главное - чтобы пользователь не потерялся. О том, что мы можем забыть о таких глобальных вещах, как нестыковки анимации, зависание ненужных пунктов меню, а главное - разрастании скриптов и дублирвании элементов дизайна на сцене - я думаю говорить не надо, это мы получаем во всей красе - и это приятно, удобно, и понятно.
Кроме тех выгод, которые мы получаем при разработке самого флеша, данный подход идеально ложится на окружение, в котором находится сайт - а именно, серверные скрипты, создающие xml-ы для него и на back-end системы, которые наполняют контент. Положим, и на то, и на другое нам - флеш-разработчикам - более или менее наплевать: мы получили xml, а как он сгенерился, через что он прошел - это уже не наши проблемы, наше дело его прочесть и интерпретировать. Тем не менее, существующая система вложенности папок с контентом на сервере - те же самые готовые пути, нам не надо ничего придумывать чтобы как-то обозначить ту или иную информацию.
Продолжение следует
Автор : Дмитрий Щипачёв (Король)
>>>Read More...
Flash и XML (Статья от Дембицкого)
Предисловие
Почему XML
Формат XML благодаря своей гибкости и универсальности завоевывает все большую популярность в качестве формата обмена данными. В Macromedia Flash объекты XML, XMLNode с пятой версии Flash практически не претерпели никаких изменений. Однако способы их использования благодаря динамично развивающемуся окружению Flash существенно эволюционировали.
Из-за особенностей Flash эффективное использование XML-объектов вполне возможно, однако при неумелом применении их употребление может нанести существенный вред проекту - как производительности, так и удобству обслуживания. Чтобы эффективно использовать XML-данные во Flash, нужно знать приемы оптимального использования, нюансы поведения и устройство объекта XML.
Аудитория
Приемы работы с XML-объектом в большинстве своем универсальны для различных версий Flash или имеют альтернативу для применения в других версиях. Описание рассчитано на людей, знакомых с программированием во Flash. Хотя знакомство с XML начинается практически с нуля, надеюсь, что разработчики, имеющие опыт работы с XML, также найдут для себя много полезного. Книга построена по принципу от «простого к сложному».
Знакомство с XML-форматом и объектами XML и XMLNode во Flash. Формат XML
Введение
Формат XML является одним из стандартизированных языков разметки документов; он рекомендован к использованию консорциумом W3C. Спецификация XML опубликована по адресу www.w3.org/XML.
Переводы спецификации на другие языки найти по адресу www.w3.org/XML/Core/Translations. Формат XML предназначен для описания данных, имеющих логическую структуру.
Сравнение с HTML
Подавляющее большинство тех, кто связан с веб-технологиями, представляет, что такое HTML-формат. XML- и HTML-форматы очень похожи. Для того чтобы быстро понять, что же такое XML, рассмотрим XML-документ в сравнении с HTML.
Любой XML-документ, так же как и HTML-документ, содержит символы разметки и данные. В XML-формате используются те же самые символы разметки, что и в HTML-документе.
Эта часть HTML-документа
0102030405
<head>
<title>
Any text...
</title>
</head>
также является и корректным XML-документом.
Это легко проверить.
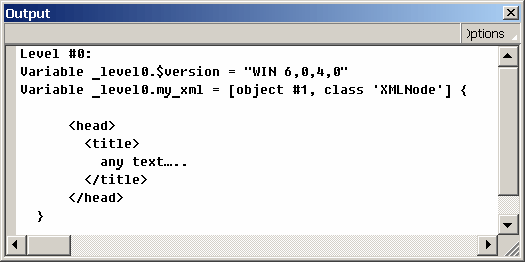
Создаем новый FLA, в первом кадре, в _root, пишем:
_root.my_xml = new XML("<head><title>any text…</title></head>");
Хозяйке на заметку | Обратите внимание на правильное именование ссылок на XML-объекты: оно состоит из двух частей, где первая часть является произвольной и характеризует XML-объект, a вторая часть всегда одинакова: _xml. Такая нотация называется венгерской и принята в ActionScript1. Использование этой нотации - признак хорошего тона в программировании на ActionScript1. Помимо улучшения читабельности кода, среда разработки Flash при использовании такой нотации помогает вводить имена встроенных свойств методов. При написании в ActionScript2 используется типизация данных. |
Тестируем (CTRL+ENTER) и заглядываем в листинг переменных: Debug - List Variables (или CTRL+ALT+V):
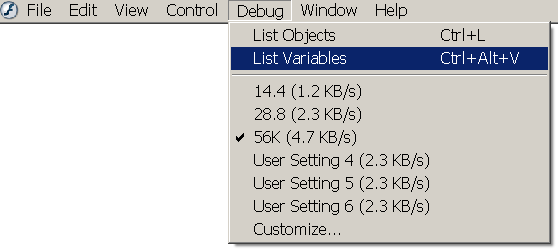
В открывшемся окне Output видим:
Здесь нужно обратить внимание на строку
Variable _level0.my_xml = [object #1, class 'XMLNode']
Мы видим, что объект #1 принадлежит к классу XMLNode. Flash распознал этот текст как корректный XML - это можно легко проверить, если после ранее написанной строки дописать:
trace(_root.my_xml.status);
При тестировании в окне Output будет выведено значение статуса XML равное нулю, что говорит о корректности.
Если при вводе данных вкралась ошибка, то статус будет иметь значение от -2 до -10. Описание перечня ошибок приводится далее, в описании свойства status объекта XML.
Статус XML - очень полезное свойство. Благодаря ему можно проверить любой XML-объект на корректность и принять меры в случае, если входящие XML-данные имеют ошибку.
Номер ошибки поможет найти конкретное место в документе XML, где эта ошибка допущена.
Типы узлов
| Тип узла | Номер типа узла |
| ELEMENT_NODE | 1 |
| ATTRIBUTE_NODE | 2 |
| TEXT_NODE | 3 |
| CDATA_SECTION_NODE | 4 |
| ENTITY_REFERENCE_NODE | 5 |
| ENTITY_NODE | 6 |
| PROCESSING_INSTRUCTION_NODE | 7 |
| COMMENT_NODE | 8 |
| DOCUMENT_NODE | 9 |
| DOCUMENT_TYPE_NODE | 10 |
| DOCUMENT_FRAGMENT_NODE | 11 |
| NOTATION_NODE | 12 |
При разборе XML-документа Flash либо приводит узлы к первому или третьему типу (как, например, это происходит с секцией CDATA), либо помещает в соответствующие объекты (как, например, атрибуты или объявление DOCTYPE). Далее по мере необходимости мы рассмотрим это подробнее.
Элементы, составляющие узел
Определим, из каких основных элементов может состоять узел XML во Flash. Как сказано выше, узлы во Flash делятся на два типа: элемент XML и текстовый узел.
Текстовый узел представляет собой любой набор символьных данных, включая пробелы, табуляции, переносы строк и т. п. Ограничения: текстовый узел не может содержать символы разметки < и >, которые следует заменять символами подстановки или помещать в секцию CDATA.
Хозяйке на заметку | Как узнать, какие символы подстановки использовать? Flash автоматически конвертирует запрещенные символы в символы подстановки, если они помещены в секцию CDATA. Отсюда простой способ - создание объекта XMLNode четвертого типа: trace(new XMLNode(4, '<>'));В данном примере будут выведены символы подстановки для символов < и >. |
Элемент XML состоит из символов разметки, имени узла и атрибутов с их значениями.
Пример узла XML первого типа без вложенных элементов:
<node_name attribute1='any value' attributeN='any value' />
Элементы:
< и > - открывающий и закрывающий символы разметки;
node_name - имя узла, может быть любым; ограничения: имя узла не должно содержать пробелов, знаков пунктуации и символов разметки < и >;
attribute1 - имя атрибута, может быть любым; атрибутов в данном примере два, но их может быть неограниченное количество или не быть вовсе; ограничения: имя атрибута не должно содержать пробелов, знаков пунктуации и символов разметки < и >;
any value - значение атрибута, может быть любым, может содержать пробелы и знаки пунктуации; обязательно должно быть заключено в кавычки.
Хозяйке на заметку | Ограничения: значение атрибута не может содержать символов разметки < и > или кавычек, их следует заменять символами подстановки. |
Более подробно о правилах создания узлов можно узнать на сайте консорциума W3C по адресу http://www.w3.org/XML/.
В некоторых случаях во Flash ограничения возможно обойти, но не стоит этого делать без крайней необходимости.
Тип 1: элемент XML (ELEMENT_NODE)
Тело XML не имеет предопределенных имен тегов, для него нет разницы - <head> или <leg>, если в примере выше заменить head на leg (закрывающие теги тоже нужно заменять), то никакой ошибки не возникнет. В HTML же имена тегов строго предопределены.
XML, в отличие от HTML, не может содержать незакрытых тегов, как, например, широко используемый без знака закрытия тег <BR> в HTML.
В XML значения атрибутов обязательно должны быть заключены в кавычки. HTML допускает возможность использования атрибутов без кавычек.
Как и в HTML, возможны две формы записи узла:
<имя_узла имя_атрибута="значение атрибута" />
и
<имя_узла имя_атрибута="значение атрибута"></имя_узла>
Тип 3: текстовый узел (TEXT_NODE)
Текстовый узел - это обычный текст, не содержащий символов разметки. Символы разметки < и > должны быть заменены соответствующими символами подстановки < > или < >. Однако в отличие от HTML, возможно использование символов разметки внутри специальной секции CDATA. В таком случае Flash при разборе XML-документа самостоятельно сконвертирует символы разметки в символы подстановки. Во Flash следующие варианты записи текстовых узлов, находящихся внутри узла text_holder, дадут одинаковый результат:
вариант 1
010203
<text_holder>
<![CDATA[<text node>]]>
</text_holder>
вариант 2
010203
<text_holder>
<text node>
</text_holder>
вариант 3
010203
<text_holder>
<text node>
</text_holder>
Это легко проверить, если написать следующий скрипт и протестировать:
<![CDATA[<text node>]>
trace(new XML("<text_holder></text_holder>"));
trace(new XML("<text_holder><text node></text_holder>"));
trace(new XML("<text_holder><text node&gt;</text_holder>"));
Мы увидим в окне Output три одинаковые строки.
Это не все сходства и отличия XML и HTML, но для продолжения знакомства этого вполне достаточно.
Структурные отношения
Иерархия XML
XML-формат допускает вложенность элементов друг в друга. Если один или несколько элементов XML расположены между тегами открытия и закрытия другого узла, то такие элементы являются вложенными (nested).
В XML вложенные элементы, по отношению к элементу, их содержащему, называются дочерними (children). Соответственно, по отношению к дочерним элементам, элемент, их содержащий, называется родительским (parent). Элементы, расположенные в одном родителе на одном уровне, называются братьями (siblings).
Любой родитель с дочерними узлами или любой дочерний элемент называется узлом (node).
Дочерние узлы зависимы от родительских. Например, если родительский узел будет программно удален, то будут удалены и его дочерние узлы.
Всегда имеется единственный узел, который содержит в себе все остальные узлы, называемый корневым узлом XML (XML root node).
Узел, c которым в данный момент производятся какие-либо действия, называется текущим узлом (current node).
С помощью XML очень удобно описывать структурированные, т. е. взаимозависимые данные. Рассмотреть это можно на примере структуры меню.
Меню может состоять из одинаковых элементов, как расположенных на одном уровне, так и вложенных друг в друга. При этом функциональность элементов может изменяться в зависимости от наличия или отсутствия дочерних элементов. Например, если элемент меню содержит дочерние элементы, то его можно отобразить как папку, а если не содержит - то как обычный пункт меню. Описать такую структуру без использования XML довольно сложно, с помощью XML - легко и быстро.
01020304050607080910111213
_root.xml_string = "<item name='item1'>";
_root.xml_string += "<item name='item2'>";
_root.xml_string += "<item name='item3' />";
_root.xml_string += "</item>";
_root.xml_string += "</item>";
_root.xml_string += "<item name='item4'>";
_root.xml_string += "<item name='item5'/>";
_root.xml_string += "</item>";
_root.my_xml = new XML(_root.xml_string);
delete _root.xml_string
if (_root.my_xml.status) {
trace("incorrect xml");
}
Хозяйке на заметку | Переменной _root.xml_string можно было присвоить сразу всю строку, но в подобном случае в дальнейшем будет неудобно просматривать или исправлять такую строку. |
Если при тестировании на CTRL+ENTER в окне Output появилось сообщение incorrect xml, значит, статус XML не равен нулю, что говорит об ошибке. В этом случае внимательно проверьте соответствие вашей записи приведенной выше.
Если сообщение не появилось, то в листинге переменных XML должен отобразиться в таком виде:
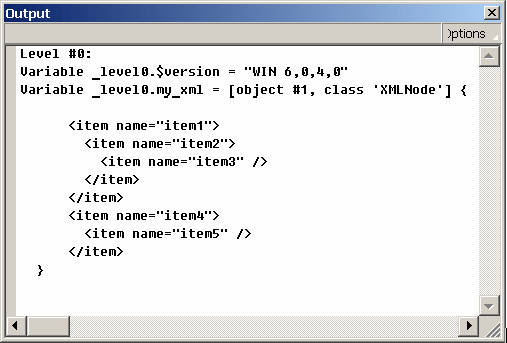
При дальнейшем программном построении меню для выбора пиктограммы пункта достаточно проверить наличие дочерних элементов у узла и, если дочерние узлы имеются, то добавить пиктограмму с изображением папки; если дочерних узлов нет, добавить пиктограмму обычного пункта меню.
Вложенность элементов друг в друга, уровень вложенности элементов, взаимное расположение элементов, находящихся на одном уровне, и другие признаки дают массу дополнительной информации о структурных взаимоотношениях узлов. Эту информацию легко получать и использовать. Структурные отношения узлов часто являются не менее значимой информацией, чем само их содержимое.
Структурные типы XML
По структурной организации XML-документы можно условно разделить на три типа: одномерные, многомерные и смешанные.
Многомерный XML-документ характеризуется тем, что его узлы могут содержать вложенные узлы того же вида и функциональности. Ярким примером такой структуры является
0102030405060708
<item name="item1">
<item name="item2">
<item name="item3" />
</item>
</item>
<item name="item4">
<item name="item5" />
</item>
Одномерная структурная организация XML-документа характеризуется тем, что узлы не имеют дочерних узлов своего вида и обычно имеют жестко установленную, иногда стандартизированную, иерархию.
0102030405060708
<head>
<title>
<field name="my_txt" text="Hello!" />
</title>
</head>
<controls>
<checkBox name="check_mc" />
</controls>
Смешанная структурная организация XML-документа представляет собой комбинацию одномерной и многомерной структур.
010203040506070809101112131415161718
<head>
<title>
<field name="my_txt" text="Hello!" />
</title>
</head>
<controls>
<checkBox name="check_mc" property="colored" />
</controls>
<menu>
<item name="item1">
<item name="item2">
<item name="item3" />
</item>
</item>
<item name="item4">
<item name="item5" />
</item>
</menu>
Подчеркиваю: разделение структурной организации условно, и производится оно по принципу допущения возможности вложенности друг в друга узлов одинакового вида и функциональности. На практике это касается, прежде всего, способов организации анализа XML-объекта и дальнейшего использования данных XML в проекте.
Объекты XML и XMLNode во Flash
Для того чтобы иметь полноценный программный доступ к данным в XML-формате, во Flash существуют два класса: XML и XMLNode. Класс XML является подклассом XMLNode, который в свою очередь является подклассом Object.
Важно! | Принадлежность объекта к классу определяет наличие той или иной функциональности у каждого экземпляра объектов этого класса. Во Flash существуют предопределенные классы, такие как MovieClip, Array, XML, XMLNode, и другие. По сути дела, экземпляры этих классов, например, Array и XMLNode, отличаются друг от друга лишь внутренней структурной организацией и набором функций и свойств, характерных для этих классов. Структурная организация объекта, как правило, формируется конструктором класса, а функции и свойства наследуются экземплярами из прототипов класса и суперклассов. В дальнейшем изучении XML во Flash часто потребуется понимание принципов объектно-ориентированного программирования (ООП). Настоящая книга не ставит целью изучение принципов ООП, и мы лишь изредка будем останавливаться на некоторых особенностях их применения к объектам XML и XMLNode. Если вам незнакомы понятия и принципы ООП или по мере изучения этой книги у вас возникнут вопросы, с этим связанные, то рекомендую изучить статьи Робина Дебреиля на сайте www.debreuil.com. Там имеются ссылки на переводы этих статей на разные языки, в том числе на русский. |
new XML()
Для создания экземпляра XML существует конструкция, синтаксис которой выглядит следующим образом:
new XML([source])
где source - строковые данные в формате XML, необязательный параметр. Пример: создание пустого объекта XML.
my_xml = new XML()
Конструктору можно передать в качестве параметра строковые данные в формате XML, которые конструктор класса превратит в объект XML:
my_xml = new XML("<example>example text</example>")
Конструктор класса всегда создает корневой узел - безымянный узел первого типа, в который помещает все остальные узлы. Собственно только корневой узел и будет принадлежать к классу XML, все дочерние узлы будут принадлежать к классу XMLNode.
Корневой узел в листинге переменных не отображается, но его можно увидеть, используя такую конструкцию:
my_xml = XML
В листинге переменных результат будет следующим:
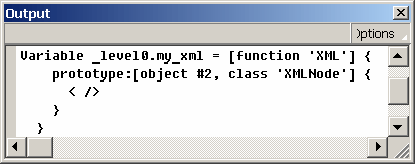
Отображается безымянный узел первого типа, не имеющий аргументов, и ссылка на объект prototype класса XMLNode.
new XMLNode()
В 6-й и 7-й версиях Flash классу XMLNode «Макромедиа» отказывала в праве на документированную жизнь. Класс фактически существовал, но в документации не описывался. В 8-й версии Flash класс XMLNode задокументирован.
Синтаксис конструктора таков:
new XMLNode(type, source)
где type - это номер типа, который может принимать значения от 1 до 12.
| 1 | ELEMENT_NODE |
| 2 | ATTRIBUTE_NODE |
| 3 | TEXT_NODE |
| 4 | CDATA_SECTION_NODE |
| 5 | ENTITY_REFERENCE_NODE |
| 6 | ENTITY_NODE |
| 7 | PROCESSING_INSTRUCTION_NODE |
| 8 | COMMENT_NODE |
| 9 | DOCUMENT_NODE |
| 10 | DOCUMENT_TYPE_NODE |
| 11 | DOCUMENT_FRAGMENT_NODE |
| 12 | NOTATION_NODE |
Для создания экземпляров XMLNode существуют два специальных метода
Для создания узлов первого типа:
XML.createElement(name)
где name - обязательный параметр, который может быть и пустой строкой.
Для создания узлов текстового типа:
XML.createTextNode(text)
где text - обязательный параметр, который может быть и пустой строкой.
По сути, функции createElement и createTextNode в плеере заданы примерно так:
010203040506
XML.prototype.createElement = function (name) {
return name == undefined ? undefined : new XMLNode(1, name)
};
XML.prototype.createTextNode = function (text) {
return text == undefined ? undefined : new XMLNode(3, text)
};
Однако эти способы не всегда удовлетворяют потребностям. Иногда требуется создать объект XMLNode из текста в формате XML. В этом случае используется конструктор класса XML с последующим получением первого потомка:
my_new_node = new XML("<node attribute='value'/>").firstChild
Объект prototype, некоторые принципы наследования
При объявлении функции всегда создаются два объекта: тело функции и объект prototype, принадлежащий этой функции. Объект prototype используется как хранилище свойств и методов класса и имеет интересные и крайне важные особенности, связанные с организацией наследования.
Во Flash-плеере при обращении к методу, свойству, переменной и т. д. их поиск происходит по следующей схеме:
| 1. | проверяется наличие в экземпляре класса; если нет, то выполняется п. 2; |
| 2. | проверяется в прототипе класса; если нет, то выполняется п. 3; |
| 3. | проверяется в прототипе вышестоящего класса; если нет, то выполняется п. 4; |
| 4. | … |
| 5. | проверяется в прототипе класса Object, если нет, п. 6; |
| 6. | вызывается функция __resolve(), если она не определена, п. 7; |
| 7. | возвращается undefined. |
Таким образом, если в прототип какого-либо класса поместить переменную, свойство или метод и если в экземпляре класса эта переменная, свойство или метод не определены, то значение будет найдено в прототипе и возвращено как значение экземпляра.
Применительно к объектам классов XML и XMLNode справедливо утверждение, что класс XML является подклассом XMLNode, который, в свою очередь, является подклассом Object. Соответственно, по этой причине любой XML-объект помимо собственных свойств и методов будет иметь доступ к свойствам и методам класса XMLNode и класса Object, а любой объект XMLNode помимо собственных свойств и методов будет иметь доступ к свойствам и методам класса Object, но не будет иметь доступа к свойствам и методам класса XML.
Методы свойства и события объектов XML и XMLNode
Реализация свойств во Flash
Прежде чем перейти к непосредственному изучению свойств XML и XMLNode, следует знать, как они реализованы во Flash. Все свойства XML имеют getter- и setter-методы. Это необходимо для предотвращения нежелательного изменения свойств объектов XML-дерева.
Например, попытка присвоить неверный тип узла не приведет к присвоению неправильного типа:
01020304
my_xml = new XML("<node />")
trace(my_xml.firstChild.nodeType)
my_xml.firstChild.nodeType = 3
trace(my_xml.firstChild.nodeType)
В результате в окне Output будет дважды выведено значение 1; это говорит о том, что попытка назначить неверное значение свойства не удалась.
Но это вовсе не значит, что никакие свойства объектов XML изменять нельзя. Нельзя изменять или удалять только такие свойства, изменение или удаление которых может привести к нарушению иерархических взаимоотношений в дереве XML.
Важно! | Любой объект во Flash может иметь собственные и унаследованные методы и свойства. Любой объект может быть добавлен в список слушателей любых событий, и ему могут быть назначены обработчики этих событий. Вышеперечисленное в итоге определяет реакцию объекта на те или иные вызовы его методов на присвоение ему новых значений свойств или на возникновение событий. Реакции определяет поведение объекта. Далее в этой книге под поведением объекта будет подразумеваться совокупность реакций объекта на события, вызовы его методов и изменение значений свойств. |
Для эффективной работы с данными в формате XML поведение объектов дерева XML организовано исходя из тех задач, которые необходимо решать:
- связь с внешними источниками данных;
- разбор текстовых данных и создание XML-объекта;
- навигация по дереву XML;
- управление данными;
- управление структурой данных;
- расширение функциональности объектов XML.
Далее именно в этом порядке будут рассмотрены свойства, методы и события объектов XML-дерева.
Связь с внешними источниками данных
Многие XML-данные получаются Flash-роликом извне. Для организации связи с внешними источниками данных предусмотрены следующие методы, свойства и события:
XML.load()
XML.getBytesLoaded()
XML._bytesLoaded
XML.getBytesTotal()
XML._bytesTotal
XML.onData()
XML.onLoad()
XML.loaded
XML.sendAndLoad()
XML.send()
XML.addRequestHeader()
XML.contentType
XML.docTypeDecl
Обратите внимание, что все они заданы для класса XML и по умолчанию недоступны для узлов XMLNode, но, разумеется, при желании их можно сделать доступными многими способами.
XML.load()
Метод. Предназначен для инициализации загрузки внешних текстовых данных в формате XML.
Синтаксис:
my_xml.load(url)
Помимо инициализации загрузки данных устанавливает свойство loaded-экземпляра XML равным false.
В качестве url может быть использован адрес любого файла или программы, которая возвращает текстовые данные в XML-формате. Возможна как относительная, так и абсолютная адресация, возможна адресация от корневой папки источника данных или от адреса, указанного в атрибуте BASE.
Абсолютная адресация
Абсолютная адресация, как правило, используется в тех случаях, когда, необходимо получать данные из иного домена, чем тот, в котором расположена HTML-страница, содержащая swf-файл. Пример:
my_xml.load("http://www.anydomain.com/xmlfiles/data.xml")
Важно! | Политика безопасности Macromedia Flash до Начиная с Подробнее с политикой безопасности можно ознакомиться на сайте производителя: www.macromedia.com/support/flash/ts/documents/security_sandbox.htm. При этом способ с применением серверного скрипта, описанный выше, не потерял своей актуальности. |
Адресация от корня сайта
Если данные находятся в том же домене, где расположен Flash-ролик, то имя домена можно заменить на символ /.
Пример
Если ролик расположен в домене www.anydomain.com, то абсолютную адресацию
my_xml.load("http://www.anydomain.com/xmlfiles/data.xml")
можно заменить на
my_xml.load("/xmlfiles/data.xml")
Данные будут загружены из того же домена, что и HTML-страница, содержащая Flash-ролик, из папки xmlfiles.
Относительная адресация
Часто бывает удобно указать адрес данных, используя относительную адресацию. Правила этой адресации аналогичны используемым в HTML, символы ../ указывают плееру на необходимость подняться на уровень выше. Можно подниматься на один, два и более уровней, используя такое обращение нужное количество раз.
Если HTML-страница и swf-файл находятся в различных папках, то адресация указывается от адреса HTML-страницы.
Адресация относительно base
При встраивании Flash-ролика в HTML-страницу в атрибутах тегов OBJECT и EMBED можно указать адрес, который будет являться базовым для относительных путей. Делается это следующим образом:
01020304050607080910
<OBJECT>
[другие параметры]
<PARAM NAME="BASE" VALUE="/any_folder/any_folder/">
[другие параметры]
<EMBED
[другие параметры]
BASE="/any_folder/any_folder/"
[другие параметры] >
</EMBED>
<OBJECT>
В нашем примере, если указать в качестве BASE адрес /xmlfiles, обращение к данным будет выглядеть следующим образом:
my_xml.load("data.xml")
Плеер достроит адрес, используя BASE, и получит данные из папки xmlfiles, находящейся в корне сайта.
Получение данных от серверных программ
Для плеера не имеет значения, берутся данные из статичного файла или их возвращают серверные программы. Но часто серверным программам необходимы дополнительные данные для генерации ответа. Эти данные можно передать в адресе запроса. Для этого после адреса ставится вопросительный знак, за которым, разделенные символом &, следуют пары переменных и их значений, разделенных, в свою очередь, знаком равенства.
Например:
my_xml.load("/counter/show.php?name=printer.swf")
В этом примере серверной программе, подсчитывающей количество просмотров Flash-роликов, передается имя просматриваемого ролика.
Разумеется, данные, передаваемые серверной программе, практически не бывают статическими, как в примере выше. Строку запроса обычно составляют, используя переменные ролика. Например:
010203
var str = "name="+_root.user_name
str+="&scores"+_root.total_scores
my_xml.load("/counter/show.php?"+str)
Так, если переменная _root.user_name содержит строку John а переменная _root.total_scores содержит цифру 56, итоговая строка запроса будет аналогична такой:
my_xml.load("/counter/show.php?name=John&scores=56")
Запрет кеширования запросов
Если использовать способы обращения, рассмотренные в предыдущем примере, то существует вероятность того, что запрос не будет направлен серверу, а ответ будет взят из кеша браузера. Чтобы исключить это, следует использовать дополнительную переменную, которая будет отличать один запрос от другого. Практика показала, что лучше всего для этого использовать функцию getTime объекта Date следующим образом:
01020304
var str = "name="+_root.user_name
str+="&scores"+_root.total_scores
str+="&random"+new Date().getTime()
my_xml.load("/counter/show.php?"+str)
Этот способ полностью гарантирует, что запрос будет отличаться от предыдущих и ответ не будет взят из кеша браузера.
Возможно, что использование запрета на кеширование со стороны Flash-ролика несколько избыточно. При правильных настройках серверных программ ролику будут возвращены данные, полученные от сервера, а не из кеша браузера. Однако наличие различных браузеров с часто неожиданным поведением, а также простая невнимательность серверных программистов могут сыграть злую шутку.
Как следствие, лучше использовать этот способ, нежели подвергать себя риску непредвиденного поведения ролика.
Использование алгоритмов сжатия
Для уменьшения объема передаваемых данных иногда применяется предварительное сжатие данных на стороне сервера, например, с использованием GZIP.
Это возможно и по отношению к XML-документам, которые запрашивает Flash-ролик.
Дело в том, что Flash-ролик не делает запрос самостоятельно, а лишь дает задание браузеру сделать этот запрос. Браузеры, делая запрос на сервер, указывают в заголовке запроса, какие форматы сжатия они поддерживают. Эти заголовки могут быть прочитаны серверной программой, после чего принимается решение о сжатии данных. Браузер, получая сжатые данные, распаковывает их и передает Flash-ролику в распакованном виде.
Таким образом, использование алгоритмов сжатия данных ложится полностью на браузер пользователя, а не на Flash-проигрыватель и может быть реализовано без каких-либо изменений во Flash-ролике. С другой стороны, придумано достаточно много различных способов осуществлять обмен сжатыми данными независимо от возможностей пользовательских браузеров.
Существуют различные реализации использования алгоритма GZIP с распаковкой данных внутри Flash-ролика. Но думаю, что одним из наиболее оригинальных решений в этом направлении является идея Марио Клингеманна, который предложил упаковывать XML-данные в сжатый swf: www.quasimondo.com/archives/000213.php. Это избавляет от необходимости распаковки данных с помощью ActionScript, так как при загрузке swf-файл с данными распаковывается Flash-плеером.
Защищенный режим
В сети передача данных в защищенном режиме возможна с использованием протокола HTTPS. Flash как, и в случае с использованием алгоритмов сжатия данных не требует особых мероприятий для организации передачи данных в защищенном режиме. Вся работа по обслуживанию HTTPS ложится на браузер. Таким образом, любой Flash-ролик, созданный для работы по протоколу HTTP, не потребует дополнительных доработок для протокола HTTPS. Требования безопасности налагают определенные ограничения на взаимодействие Flash-ролика на безопасной странице с данными; подробнее об этом можно прочесть на сайте производителя: www.macromedia.com/support/flash/ts/documents/security_sandbox.htm.
XML.sendAndLoad()
Метод. В отличие от XML.load(), конвертирует объект XML в строку и посылает эту строку серверной программе методом POST. Также требуется указать XML-объект - получатель ответа серверной программы. Этим объектом может быть и текущий XML-объект.
Синтаксис:
my_xml.sendAndLoad(url, target_xml)
После вызова этого метода события onData и onLoad произойдут в target_xml, а не в XML-объекте - инициаторе загрузки.
XML.send()
Метод. Его отличие от предыдущего состоит в том, что ответ серверной программы возвращается не XML-объекту Flash-ролика, а окну браузера. Соответственно, требуется указывать, в какое окно браузера загрузить ответ сервера. По умолчанию указано _self.
Синтаксис:
my_xml.send(url [, window])
По сути дела, этот метод аналогичен команде getURL с передачей на сервер строки XML методом POST.
Хозяйке на заметку | Как поступить в том случае, когда возникает необходимость отправки на сервер данных помимо строки XML, например, указать серверу, какие действия с этим XML требуется произвести? Любые наборы переменных и их значений |
XML.getBytesLoaded(), XML._bytesLoaded, XML.getBytesTotal(), XML._bytesTotal
Для отслеживания состояния процесса загрузки данных в объекте XML существуют две функции: getBytesLoaded и getBytesTotal. Они возвращают объем загруженных данных в байтах и объем всего файла в байтах.
В плеере они реализованы примерно следующим образом:
010203040506
XML.prototype.getBytesLoaded = function () {
return this._bytesLoaded
}
XML.prototype.getBytesTotal = function () {
return this._bytesTotal
}
Свойства _bytesLoaded и _bytesTotal, которые имеются у объекта XML, не документированы. Это значит, что их использование влечет за собой риск того, что в последующих версиях Flash-плеера они будут недоступны, хотя это маловероятно.
Аналогичные свойства отсутствуют у других объектов, имеющих функции обслуживания предзагрузки, например, у MovieClip. И отсутствие описания этих свойств XML в документации скорее всего мотивируется тем, что было бы нелогично реализовывать по-разному одинаковую функциональность.
На практике функции обслуживания предзагрузки используются для получения процента загрузки с помощью простой конструкции:
010203
var total = my_xml.getBytesTotal()
var loaded = my_xml.getBytesLoaded()
var percents = Math.floor(loaded/total*100)
Однако это далеко не все возможности, которые открываются благодаря данным функциям. Например, при загрузке больших XML-документов несложно реализовать прогноз требуемого на загрузку времени и вывести соответствующее сообщение пользователю. Об этом и о других возможностях предзагрузки будет подробнее рассказано в последующих главах этой книги.
XML.onData()
Это первое событие, которое происходит по окончании загрузки XML-данных. Функция onData определена в прототипе класса XML и выглядит примерно следующим образом:
010203040506070809
XML.prototype.onData = function (source) {
if (source == null) {
this.onLoad(false);
} else {
this.parseXML(source);
this.loaded = true;
this.onLoad(true);
}
}
В качестве аргумента source функция получает все пришедшие данные.
Если никаких данных не получено, то вызывается событие onLoad с передачей false в качестве аргумента.
Если пришли данные, то вызывается процедура разбора пришедших данных, затем свойство loaded устанавливается равным true и вызывается событие onLoad с передачей ему true в качестве аргумента.
Функцию onData при желании можно переназначить как классу XML, так и любому конкретному экземпляру XML.
XML.onLoad()
Как видно из описания XML.onData, событие onLoad вызывается в любом случае, даже если данные не получены. Меняется лишь значение аргумента.
К моменту вызова события onLoad полученные данные уже разобраны методом parseXML и помещены в тело экземпляра XML. Используется событие onLoad обычно следующим образом:
010203040506070809101112131415
my_xml = new XML()
my_xml.load("/xmlfiles/data.xml")
my_xml.onLoad=function(success) {
if(!success || this.status){
return this.customErrorHandler(this.status, success)
}
this.customParsingProcedure()
}
my_xml.customParsingProcedure = function (){
// custom actions here
}
my_xml.customErrorHandler = function (status, success){
trace("loaded: " + success +" valid: " + !this.status)
// custom actions here
}
В первую очередь проверяется успешность загрузки XML-данных (аргумент success) и отсутствие ошибок при разборе XML-документа (свойство status экземпляра XML). Если хотя бы одно из вышеперечисленных условий не возвращает true, то дальнейшая обработка, как правило не имеет смысла и выполнение onLoad прерывается выходом в пользовательский обработчик ошибок, в данном случае это пользовательский метод customErrorHandler. Если документ успешно загружен и он соответствует требованиям XML формата, то можно осуществить дальнейшую его обработку пользовательским методом customParsingProcedure.
XML.loaded
Свойство. Может иметь следующие значения:
undefined - если не предпринималось попыток загрузить внешние данные.
false - если предпринята попытка загрузить внешние данные, но эти данные еще не загружены, либо если произошла ошибка загрузки данных. Это значение устанавливается при вызове метода XML.load.
true - если попытка получить внешние данные оказалась успешной. Это значение устанавливается при вызове метода XML.onData.
XML.addRequestHeader()
Начиная с 7-й версии плеера появилась возможность добавлять собственные теги в заголовок запроса.
Синтаксис:
my_xml.addRequestHeader(header_name, header_value)
либо с использованием массива:
0102
headers_array =[header_1name, header_1value, header_n_name, header_n_value]
my_xml.addRequestHeader(headers_array)
На момент написания этой книги использование заголовков HTTP-запроса считается довольно экзотическим способом передачей дополнительных данных для серверных программ и с успехом заменяется передачей данных через строку запроса или добавление специальных узлов в дерево XML.
XML.contentType
Свойство. Представляет MIME тип данных, передаваемых через заголовок документа.
По умолчанию имеет значение application/x-www-form-urlencoded.
За всю мою практику я ни разу не столкнулся с необходимостью изменять это свойство.
XML.docTypeDecl, XML.xmlDecl
Flash никак не интерпретирует узлы XML, содержащие объявления типа документа и анализаторы достоверности. Такие узлы в текстовом виде помещаются в соответствующие свойства XML-объекта и никак не влияют на разбор или декодировку данных.
Пример узлов объявления типа документа:
0102
<?xml version="1.0" encoding="windows-1251"?>
<!DOCTYPE Imprimatur SYSTEM "/entities.dtd">
В данном примере указание кодировки «windows-1251» никак не повлияет на разбор этого XML-документа во Flash. Детальнее практика применения различных кодировок будет рассмотрена далее в этой книге.
Анализ текстовых данных и создание XML-объекта
Текстовые данные в формате XML не становятся сами по себе объектом XML. Чтобы превратить текстовые данные в XML-объект, существует специальная процедура анализа текстовых данных, называемая парсингом или первичным парсингом.
Для организации процедуры парсинга класс XML имеет следующие свойства и методы:
XML.parseXML()
XML.status
XML.ignoreWhite
Первичный парсинг XML-документа - это анализ текстовых данных в формате XML и помещение этих данных в соответствующие объекты экземпляра XML, а также другие действия, в конечном итоге формирующие экземпляр XML-объекта.
Например, XML-документ следующего содержания:
<item name="text">Hello world!</item>
после парсинга будет представлять собой четыре объекта:
- объект XML (класс XML)
- узел XML с именем «item» (класс XMLNode, первый тип)
- объект attributes узла item (класс Object)
- текстовый узел (класс XMLNode, третий тип)
Все эти объекты будут связаны между собой различными ссылками друг на друга и будут содержать соответствующие данные, полученные из XML-документа.
В процессе парсинга не создаются никакие внешние ссылки на эти объекты. Доступ к ним можно получить только через ссылку на экземпляр объекта XML.
Процедура парсинга осуществляется методом XML.parseXML.
XML.parseXML()
Метод. Осуществляет парсинг текстовых данных в формате XML.
Синтаксис:
my_xml.parseXML(source)
Ничего не возвращает, а изменяет содержимое текущего XML-объекта.
Ошибочно пытаться сделать таким образом:
my_xml = my_xml.parseXML("<item />")
В этом случае, поскольку метод parseXML ничего не возвращает, my_xml примет значение undefined.
Правильное использование:
my_xml.parseXML("<item />")
Во встроенных функциях метод parseXML используется:
- в конструкторе класса XML, если в качестве параметра передана соответствующая строка;
- в обработчике события onData.
Метод parseXML в процессе разбора устанавливает значение свойству status экземпляра XML.
Если в процессе разбора обнаруживается ошибка, то процедура парсинга прерывается. Созданные процедурой парсинга новые узлы не удаляются.
XML.status
Свойство. Устанавливается процедурой парсинга. Принимает значение 0 при отсутствии ошибок. В случае ошибки парсинга принимает значение от −2 до −10, каждое из которых указывает на тип ошибки.
Вот перечень значений, которые может принимать status:
| Описание | Статус |
| Нет ошибок: синтаксический анализ закончен успешно | 0 |
| Раздел CDATA не был закончен должным образом | −2 |
| Объявление XML не было закончено должным образом | −3 |
| Объявление DOCTYPE не было закончено должным образом | −4 |
| Комментарий не был закончен должным образом | −5 |
| XML-элемент сформирован неправильно | −6 |
| Не хватает памяти | −7 |
| Значение атрибута не было закончено должным образом | −8 |
| Тег начала не был согласован с конечным тегом | −9 |
| Конечный тег указан без соответствующего начального тега | −10 |
Навигация
Для организации навигации по дереву XML класс XMLNode имеет следующие свойства:
XMLNode.firstChild
XMLNode.lastChild
XMLNode.childNodes
XMLNode.nextSibling
XMLNode.previousSibling
XMLNode.parentNode
XMLNode.attributes.id
Суть навигации сводится к тому, что имея ссылку на объект XML или любой его узел можно получить ссылку на структурно связанные с ним узлы.
Важно! | Переход с одного узла на другой - это получение ссылки на узел XML с использованием навигационных свойств другого узла XML или объекта XML. Подняться на шаг в иерархии узлов означает перейти на родительский уровень. Родитель у узла может быть только один. Опуститься на шаг в иерархии узлов означает перейти на уровень потомков текущего узла. Переход возможен:
Глубина узла - степень вложенности узла в другие узлы: фактически это количество предков данного узла в иерархии XML. |
Дочерние, братские, родительские узлы
Каждый узел XML-объекта имеет структурные связи с другими узлами. Однако каждый узел имеет ссылки не на все остальные узлы, а только на близлежащие в иерархии: на родительские, дочерние и братские узлы.
Соответственно, у каждого узла имеются ссылки на:
- на дочерние узлы
1. node_xml.firstChild - первый потомок в узле node_xml 2. node_xml.lastChild - последний потомок в узле node_xml 3. node_xml.childNodes - массив всех потомков узла node_xml - на братские узлы
1. node_xml.nextSibling - следующий брат узла node_xml 2. node_xml.previousSibling - предыдущий брат узла node_xml - на родительский узлы
1. node_xml.parentNode - родительский узел узла node_xml
Пример навигационных переходов
Чтобы проиллюстрировать использование навигационных свойств для переходов по узлам, создадим объект XML и затем, зная структуру XML-данных, последовательно получим ссылку на каждый из узлов этого XML и выведем в окно Output значение атрибута name каждого узла:
01020304050607080910111213141516171819202122232425262728293031323334353637383940
// создаем объект XML:
_root.xml_string = "<item name='item1'>";
_root.xml_string += "<item name='item2'>";
_root.xml_string += "<item name='item3' />";
_root.xml_string += "</item>";
_root.xml_string += "</item>";
_root.xml_string += "<item name='item4'>";
_root.xml_string += "<item name='item5'/>";
_root.xml_string += "</item>";
_root.my_xml = new XML(_root.xml_string);
delete _root.xml_string
if (_root.my_xml.status) {
trace("incorrect xml");
}
// НАВИГАЦИЯ
// переходим на объект XML - это самый верхний узел в иерархии узлов XML
_root.link_to_node = _root.my_xml
// опускаемся на шаг, на первого потомка объекта XML:
_root.link_to_node = _root.link_to_node.firstChild
trace(_root.link_to_node.attributes.name)
// опускаемся на шаг, на первого потомка
_root.link_to_node = _root.link_to_node.firstChild
trace(_root.link_to_node.attributes.name)
// опускаемся на шаг, на первого потомка
_root.link_to_node = _root.link_to_node.firstChild
trace(_root.link_to_node.attributes.name)
// поднимаемся на шаг
_root.link_to_node = _root.link_to_node.parentNode
trace(_root.link_to_node.attributes.name)
// поднимаемся на шаг
_root.link_to_node = _root.link_to_node.parentNode
trace(_root.link_to_node.attributes.name)
// переходим на следующего брата
_root.link_to_node = _root.link_to_node.nextSibling
trace(_root.link_to_node.attributes.name)
// опускаемся на шаг, на первого потомка
_root.link_to_node = _root.link_to_node.firstChild
trace(_root.link_to_node.attributes.name)
delete _root.link_to_node
Затем тестируем.
В окне Output должен появиться результат:
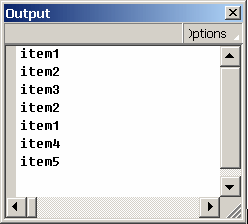
Вначале мы пошагово спустились до третьего узла, затем пошагово вернулись наверх, к первому узлу, затем с первого узла перешли на следующего брата - на четвертый узел - и спустились к пятому узлу. Мы видим, что переменная _root.link_to_node поочередно содержала ссылку на эти узлы XML и нам были доступны их атрибуты.
По окончании обхода мы удалили эту переменную командой delete _root.link_to_node.
Важно! | Стоит заметить, что командой delete _root.link_to_node мы удалили только ссылку на узел, но не сам узел. Во Flash объекты и ссылки на них - это разные вещи. Удаляя ссылку на объект, мы удаляем сам объект только в том случае, если на этот объект больше не остается никаких ссылок. Это легко проиллюстрировать примером: _root.my_object = new Object()_root.my_link_to_object = _root.my_objectdelete _root.my_objecttrace(_root.my_link_to_object)В окне Output будет выведена информация о том, что такой объект существует. Объект также будет виден в листинге переменных. Почему так происходит? Дело в том, что строка _root.my_object = new Object()не создает объект my_object. На самом деле создается безымянный объект, а в переменную my_object только помещается ссылка на него. Строка _root.my_link_to_object = _root.my_objectне влечет за собой создания дублирующего объекта, а только помещает ссылку на все тот же безымянный объект в переменную my_link_to_object. Во Flash у программиста нет прямого способа удаления объекта. Любой объект удаляется только сборщиком мусора, и только в случае, если на него не осталось ссылок. Однако это поведение относится исключительно к наследникам класса Object. Если переменная содержит простое значение, например, цифру или строку, то происходит дублирование значения переменной и ссылка на это значение всегда остается единственной. Удаляя ссылку на такое значение, можно с уверенностью сказать, что и само значение будет удалено. В случае с узлом XML наша ссылка была единственной пользовательской ссылкой на узел, но остались многочисленные ссылки на этот узел из других узлов, созданные плеером автоматически при парсинге XML-данных, поэтому узел не удалился. Понимание этого механизма может сэкономить массу времени при программировании на ActionScript. |
Представленный способ обхода узлов XML трудоемок в программировании и обслуживании, не предусматривает возможности изменения иерархии XML-дерева и, как следствие, на практике его не используют. Далее будут рассмотрены другие способы обхода дерева XML, исключающие эти недостатки.
Атрибут id
Среди навигационных свойств id - идентификатор узла - стоит особняком. Это связано с существенными отличиями его реализации и использования от остальных навигационных свойств.
id - специальный атрибут узла. Может быть и цифровым и строковым. Должен быть уникальным для каждого узла объекта XML. Если в узлах XML-объекта указаны атрибуты id, то при парсинге они будут распознаны, и будут созданы одноименные переменные в объекте XML, а также в эти переменные будут помещены ссылки на узлы, содержащие эти идентификаторы.
Если же атрибуты id не будут уникальны, то при парсинге соответствующая переменная будет перезаписана столько раз, сколько встретится один и тот же id и в итоге эта переменная будет иметь значение последнего узла с таким id.
Фактически наличие id у узла позволяет обращаться напрямую к любому узлу XML, используя этот идентификатор:
01020304050607080910111213141516
xml_string = "<item id='1' name='item1'>";
xml_string += "<item id='2' name='item2'>";
xml_string += "<item id='3' name='item3' />";
xml_string += "</item>";
xml_string += "</item>";
xml_string += "<item id='4' name='item4'>";
xml_string += "<item id='5' name='item5'/>";
xml_string += "</item>";
_root.my_xml = new XML(xml_string);
delete xml_string;
if (_root.my_xml.status) {
trace("incorrect xml");
}
for (i=1; i<6; i++) {
trace(i+" - "+_root.my_xml[i].attributes.name);
}
При тестировании этого примера в окне Output должно появиться следующее:
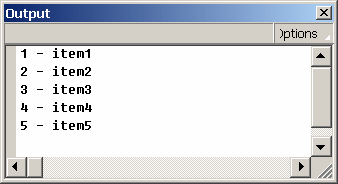
Значение такой возможности трудно переоценить. В некоторых случаях использование id повышает во много раз производительность программ и значительно упрощает процесс программирования.
В дальнейшем мы подробно рассмотрим приемы работы с этим идентификатором.
Как уже было сказано выше, атрибут id распознается во время процедуры парсинга, однако это не единственный путь. Природа id проста - это находящиеся в корне XML-объекта обычные ссылки на узлы этого XML-объекта. Поэтому подобные ссылки можно в любой момент создавать, изменять или удалять. В дальнейших примерах это будет неоднократно использовано.
В
Код, приведенный выше, в
01020304
var map = _root.my_xml.idMap;
for (i=1; i<6; i++) {
trace(i+" - "+map[i].attributes.name);
}
Причем следует заметить, что, видимо, по ошибке свойство idMap не было добавлено в intrinsic-класс, поэтому если переменная, ссылающаяся на объект XML, типизирована, то обращение к свойству idMap вызовет ошибку компилятора:
0102
var my_xml:XML = new XML()
var map:Object = my_xml.idMap;
Сообщение об ошибке:
**Error** Scene=Scene 1, layer=Layer 1, frame=1:Line 2: There is no property with the name 'idMap'.
var map:Object = my_xml.idMap;
Эту проблему легко обойти:
0102
var my_xml:XML = new XML()
var map:Object = my_xml["idMap"];
Другой, более корректный способ - указание публичной переменной в подклассе XML, если вы такой делаете.
Ни в коем случае не рекомендую изменять intrinsic-класс. Это хоть и избавит вас от проблемы, но может доставить много хлопот другим разработчикам, которым придется работать с вашим кодом.
Доступ к данным
Для полноценного доступа к информации, находящейся в объекте XML, класс XMLNode содержит следующие объекты, свойства и методы:
XMLNode.nodeName
XMLNode.nodeType
XMLNode.attributes
XMLNode.nodeValue
XMLNode.hasChildNodes
XMLNode.toString()
XMLNode.nodeName
Свойство. Строковый тип, представляющий имя узла XML.
Например, узел
<item name="name" />
будет иметь значение свойства nodeName, равное item.
После стандартного парсинга nodeName будет только у узлов первого типа. Текстовые узлы имеют значение этого свойства, равное null.
Данное свойство может программно изменяться.
Flash-плеер не ограничивает возможность задания аналогичного свойства текстовым узлам:
010203
my_xml = new XML("hello")
my_xml.firstChild.nodeName = "item"
trace(my_xml.firstChild.nodeName);
При тестировании в окне Output будет выведена строка item - говорит о том, что присвоение прошло успешно.
Таким образом, нет гарантии того, что узел, имеющий непустое значение свойства nodeName, является узлом первого типа.
Поскольку корневой узел XML, являясь узлом первого типа, имеет значение этого свойства равным null, то нельзя однозначно утверждать, что узел, имеющий значение nodeName, равное null, является текстовым узлом:
0102
my_xml = new XML("hello")
trace(my_xml.nodeName)
Для корректного определения типа узла используется свойство nodeType.
XMLNode.nodeType
Свойство. Может иметь значение 1 или 3. Характеризует тип узла, где первый тип - это узел XML, второй тип - текстовый узел.
Использование:
type_of_current_node = node_xml.nodeType
Изменить это свойство невозможно. Только для чтения.
XMLNode.attributes
Свойство. Ссылка на объект, содержащий атрибуты узла первого типа. Атрибут может быть один, их может быть несколько или не быть вовсе. Количество атрибутов и объем данных, которые будут содержать атрибуты, никак не ограничен. Однако на практике рекомендуется не перегружать этот объект данными.
Любые данные в атрибутах узла непосредственно после парсинга имеют строковый тип.
Объект attributes узла
<item name="name" text="any text" num="545" />
будет представлять собой объект вида
{name:"name", text:"any text", num:"545"}
Хозяйке на заметку | Кажущаяся похожесть attributes на обычный объект класса Object обманчива. Это весьма странный объект, поскольку он не является потомком класса Object (!) и не наследует методов этого класса. Именно поэтому, например, создать пользовательское свойство в объекте attributes напрямую нельзя, поскольку метода addProperty у объекта attributes не существует. Для понимания того, что собой представляет attributes, определим его как объект аналогичный объектам класса Object, но лишенный конструктора класса и ссылки на прототип класса. Чтобы наглядно увидеть разницу между attributes и обычным объектом, можно провести следующий эксперимент: my_xml = new XML("<item1 text='text1' /><item2 />")my_xml.firstChild.nextSibling.attributes = {text:"text2"}trace(my_xml);В окне Output будет выведено сообщение: <item1 text="text1" /><item2 text="text2" __proto__="[object Object]" constructor="[type Function]" />Такая реализация attributes, с моей точки зрения, направлена на снижение потребления машинных ресурсов объектами XML. |
Однако атрибутам можно присваивать данные любого типа, как и любой другой переменной
01020304
my_xml = new XML("<item age='55'>")
trace(typeof my_xml.firstChild.attributes.age)
my_xml.firstChild.attributes.age = parseInt(my_xml.firstChild.attributes.age)
trace(typeof my_xml.firstChild.attributes.age)
При тестировании получим в окне Output:
string
number
Начальный строковый тип данных атрибута age успешно преобразован в цифровой тип.
XMLNode.nodeValue
Свойство текстовых узлов. Возвращает декодированное значение узла.
На практике довольно часто, например, при необходимости задать некому текстовому полю текст из текстового узла, присваивают непосредственно узел:
my_txt.text = my_xml.firstChild.firstChild
Плеер в таком случае производит преобразование типов: узел XML преобразуется в строку командой toString. Но это далеко не всегда верно, что можно увидеть на примере:
010203
my_xml = new XML("<item><Hello world></item>")
trace(my_xml.firstChild.firstChild.toString())
trace(my_xml.firstChild.firstChild.nodeValue)
При тестировании в окне Output будет выведено сообщение:
<Hello world>
<Hello world>
nodeValue и toString не всегда возвращают одинаковое значение. Преобразование, используемое в nodeValue снимает необходимость декодирования символов подстановки. Более того, за исключением пользовательских методов, это единственный путь декодирования символов подстановки в текстах, и его можно применять для обслуживания других объектов.
В файлах справки указывается, что nodeValue - это свойство «только для чтения» и что задать это свойство узлам первого типа нельзя:
"If the XML object is an XML element (nodeType is 1), nodeValue is null and read-only."
Но хотя Flash-плеер и не создает узлам первого типа свойство nodeValue, имеющее собственные getter- и setter-функции, не существует запрета на создание одноименной переменной в этом узле:
010203
my_xml = new XML("<hello />");
my_xml.firstChild.nodeValue = "<500>";
trace(my_xml.firstChild.nodeValue);
В Output будет выведена строка <500>.
Присвоенные таким образом узлам первого типа значения nodeValue не отображаются в листинге переменных или при преобразовании toString.
В результате возможна ситуация, которая начинающего может поставить в тупик:
010203
my_xml = new XML(" <item />Hello world!")
my_xml.firstChild.nextSibling.nodeValue = "Goodbye world!"
trace(my_xml.firstChild.nextSibling.nodeValue)
Команда trace будет выдавать новое значение nodeValue:
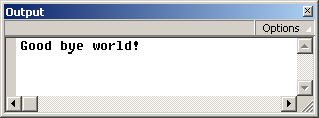
Но в листинге переменных и при отправке данных на сервер будет сохраняться старое значение:
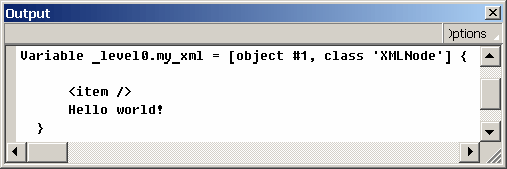
Все это происходит по причине одного незамеченного пробела перед символом < и возможности создания переменной nodeValue в узлах первого типа.
XMLNode.hasChildNodes
Свойство. Boolean. Только для чтения. В плеере реализовано примерно следующим образом:
010203
XMLNode.prototype.addProperty("hasChildNodes", function (){
return this.firstChild != undefined
}, null)
Поскольку свойство firstChild нельзя изменить пользовательскими методами, то такая конструкция вполне корректна.
XMLNode.toString()
Метод. Возвращает текстовое представление XML-объекта.
Любые операции с XML-объектами, где требуется преобразование их типа в строковый, используют этот метод.
Во Flash преобразование типов автоматическое. Даже нововведения в ActionScript 2 незначительно изменили эту ситуацию:
010203
my_xml = new XML("<item>")
my_str="text"+my_xml
trace(my_str);
В итоге, методы преобразования типов оказываются в числе самых часто вызываемых методов во Flash.
Важно! | Как известно, встроенные методы Flash могут быть подменены на пользовательские, которые, возможно, будут значительно проигрывать в производительности. Методы преобразования типов не так часто используются явно, но довольно часто могут вызываться встроенными методами. Замена метода преобразования типов может привести к существенному снижению производительности ролика, при том, что никаких видимых причин этого не будет. Стоит прислушаться к рекомендациям не заменять встроенные методы преобразования типов на пользовательские и вообще подходить к замене встроенных методов очень аккуратно и только в крайних случаях: это нерекомендуемая практика. |
Разделение именных пространств
// TODO
XMLNode.namespaceURI
Свойство. Возвращает URI (Uniform Resource Identifiers) узла XML. Появилось в
XMLNode.prefix, XMLNode.localName
В
В
Свойство prefix. Возвращает префикс имени узла XML, если имя узла содержит разделитель двоеточие.
Пример:
0102
my_xml = new XML("<prefix_value:local_name_value />");
trace(my_xml.firstChild.prefix); // prefix_value
Если имя узла не содержит разделителя двоеточие, возвращается пустая строка.
Свойство localName возвращает локальное имя узла XML, если имя узла содержит разделитель двоеточие.
Пример:
0102
my_xml = new XML("<prefix_value:local_name_value />");
trace(my_xml.firstChild.localName); // local_name_value
Если имя узла не содержит разделитель Разделение именных пространств, возвращается имя узла.
XMLNode.getPrefixForNamespace(), XMLNode.getNamespaceForPrefix()
// TODO
0102030405060708091011121314
str= "<document>"
str += "<bk:book xmlns:bk='urn:samples'>";
str += "<bk:ISBN>1-861001-57-5</bk:ISBN>";
str += "<title>Pride And Prejudice</title>";
str += "</bk:book>";
str+= "</document>"
foo = new XML(str);
delete str;
var node = foo.firstChild.firstChild
trace(node.prefix);
trace(node.localName);
trace(node.namespaceURI);
trace(node.getPrefixForNamespace("urn:samples"));
trace(node.getNamespaceForPrefix("bk"));
Изменение структуры данных
Для изменения структуры дерева XML используются следующие методы:
XMLNode.appendChild()
XMLNode.insertBefore()
XMLNode.cloneNode()
XMLNode.removeNode()
Важно! | Методы изменения структуры данных явно создавались одним человеком, причем совсем не тем, который делал все остальное, и являют собой образец того, как не надо делать. Методы appendChild, insertBefore, removeNode ничего не возвращают, что крайне неудобно. Метод appendChild позволяет добавлять дочерние узлы текстовым узлам, что противоречит не только спецификации XML, но и здравому смыслу. Убедитесь сами: my_xml = new XML("Hello world!"); node = my_xml.firstChildnode.appendChild(new XMLNode(3, "Goodbye world!"))trace(node.lastChild)node=node.lastChildnode.appendChild(new XMLNode(3, "Hello again!"))trace(node.lastChild)delete nodetrace("---");trace(my_xml);В этом примере дочерние узлы успешно создаются, но метод toString их не отображает, и в листинге переменных вы их не увидите, что также добавляет пикантности ситуации. Метод insertBefore требует избыточных данных: второй аргумент этого метода явно лишний, и указание родительского объекта в качестве this не отвечает сущности этого метода. Если мне приходится работать с изменением структуры XML-дерева, я обязательно создаю собственные методы и пользуюсь ими. В дальнейшем мы рассмотрим варианты реализации пользовательских методов, предназначенных для изменения структуры XML-дерева. |
XMLNode.appendChild()
Метод. Перемещает узел XML из объекта, в котором он находится, в узел XML, который вызвал этот метод. Перемещенный узел помещается последним в массив дочерних узлов, т.е. вставленный узел будет всегда узлом lastChild текущего узла. Этот метод ничего не возвращает.
Синтаксис:
my_xml.appendChild(node_xml)
где, my_xml - любой XML узел (не рекомендуется применять к текстовым узлам)
node_xml - вставляемый узел, объект класса XMLNode.
XMLNode.insertBefore()
Метод. Перемещает узел XML из объекта, в котором он находится, в узел XML, который вызвал этот метод. Перемещенный узел помещается перед узлом, указанном во втором аргументе. Этот метод ничего не возвращает.
Синтаксис:
my_xml.insertBefore(node_xml, before_node_xml)
где: my_xml - любой XML узел, содержащий дочерние узлы;
node_xml - вставляемый узел, объект класса XMLNode;
before_node_xml - узел, перед которым следует вставить node_xml.
XMLNode.cloneNode()
Метод. Создает и возвращает копию текущего узла. Однако следует учесть, что это не точная копия: новый узел не имеет ссылок на родительские и братские узлы, а также может не иметь дочерних узлов, если не передать true в качестве аргумента.
Синтаксис:
new_node_xml = my_xml.cloneNode(deep)
где new_node_xml - переменная, в которую будет помещена ссылка на новый узел;
my_xml - любой узел XML;
deep - аргумент, указывающий на необходимость дублирования дочерних узлов.
Поскольку вновь созданный дубликат узла не имеет никаких ссылок на родительские или братские узлы, то обязательно использование присвоения возвращаемого методом результата. В противном случае вновь созданный дубликат не будет иметь ссылок, не будет никакой возможности к нему программно обратиться и он будет немедленно удален.
XMLNode.removeNode()
Метод. Удаляет узел и его дочерние узлы из дерева XML. Не возвращает ничего.
Синтаксис:
my_xml.removeNode()
где my_xml - любой узел XML в дереве, за исключением корневого.
Унаследованные свойства и методы
Как и другие встроенные классы, классы XML и XMLNode можно расширять, добавляя собственную функциональность. Для этих целей используются свойства и методы, унаследованные от класса Object.
Рассмотрим детальнее, что собой представляет конструктор класса Object, его prototype и какое влияние это оказывает на объекты - наследники этого класса, в первую очередь, на объекты классов XML и XMLNode.
Класс Object
Для того чтобы посмотреть содержимое конструктора класса Object и его prototype, будем использовать недокументированную функцию ASSetPropFlags.
Хозяйке на заметку | Если вы раньше никогда не сталкивались с недокументированной функцией ASSetPropFlags, то предлагаю провести небольшой эксперимент. Поместите этот скрипт в первом кадре нового FLA и в режиме тестирования загляните в листинг переменных. Вы будете удивлены. ASSetPropFlags(_global, null, 6, 1); for (i in _global) {ASSetPropFlags(_global[i], null, 6, 1);for (j in _global[i]) {ASSetPropFlags(_global[i][j], null, 6, 1);for (k in _global[i][j]) {ASSetPropFlags(_global[i][j][k], null, 6, 1);}}}Ранее скрытые объекты и их содержимое станут видимы. ASSetPropFlags управляет не только видимостью объектов, но также возможностью их удаления или перезаписи. Подробности можно узнать из статей:
|
Если обойти сам Object и его экземпляр циклом for..in.., предварительно открыв для такого обхода Object и Object.prototype с помощью ASSetPropFlags:
010203040506070809101112
ASSetPropFlags(_global, "Object", 6, 1);
ASSetPropFlags(Object, null, 6, 1);
trace("\tObject:");
for (i in Object) {
trace(typeof Object[i]+":\t"+i);
}
trace("\n\tObject.prototype:");
ASSetPropFlags(Object.prototype, null, 6, 1);
for (i in Object.prototype) {
trace(typeof Object.prototype[i]+":\t"+i);
}
delete i;
В окне Output при тестировании получим следующий результат:
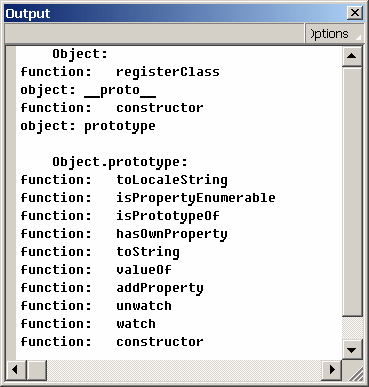
Первая часть - это объекты содержащиеся непосредственно в функции конструктора Object. Они не наследуются другими объектами от этого класса, но конструкторы других классов имеют некоторые аналогичные свойства, поскольку также являются экземплярами класса Function.
Object.registerClass - статический метод функции Object.
Ссылка на registerClass просто помещена в функцию Object, конструкторы классов XML и XMLNode не имеют аналогичной функции.
Важно! | Может ли функция помимо собственно тела содержать в себе еще что-нибудь? Это, безусловно, возможно и широко используется. Более того, каждая функция всегда имеет ссылки на другие объекты. Любая функция - это объект класса Function, в свою очередь являющегося наследником класса Object. Таким образом, можно сказать, что любая функция - это всегда объект класса Object, содержание и поведение которого расширено классом Function. |
Object.prototype - поскольку Object является функцией, то, как и любая функция, он имеет ссылку на собственный объект prototype. Конструкторы классов XML и XMLNode также являются функциями и имеют аналогичные объекты.
Object.constructor - ссылка на конструктор объекта. Поскольку Object является функцией, его конструктором является Function.
Проверим в новом FLA:
trace(Object.constructor === Function) // true
Object.__proto__ - ссылка на объект prototype конструктора класса. Поскольку у Object конструктор класса Function, то его __proto__ ссылается на Function.prototype.
Проверим в новом FLA:
trace(Object.__proto__ === Function.prototype) // true
Вторая часть - объекты содержащиеся в объекте prototype класса Object.
Если заглянуть в листинг переменных после тестирования скрипта обхода циклом for..in.. прототипа Object, то обнаружим:
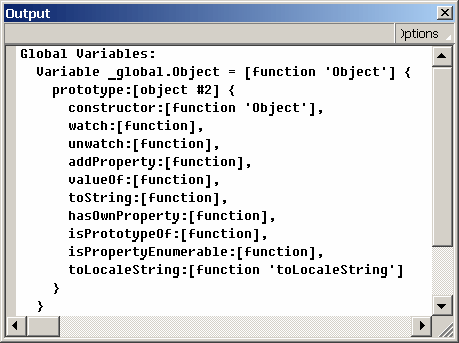
В листинге класс Object стал видимым, но внутри Object отобразился только объект prototype. Метод registerClass и объекты __proto__ и constructor не отобразились по причине того, что процедура, которая выводит данные в окно Output, их игнорирует. Обратите внимание на то, что constructor, находящийся непосредственно в Object, и constructor, находящийся внутри Object.prototype, - это разные вещи.
То, что находится вне объекта prototype, наследоваться дочерними классами не будет. Все находящееся внутри prototype может быть унаследовано другими классами, в том числе и классами XML и XMLNode.
Важно! | Следует учесть, что наследуется не все. Например, функция toString у объектов классов XML и XMLNode другая, нежели у Object. Ранее, в разделе этой книги «Объект prototype, некоторые принципы наследования» рассказывалось, как и почему это происходит. |
Наследуемые свойства и методы класса Object
Практически все объекты во Flash являются наследниками класса Object. Классы XML и XMLNode не исключение. Поэтому любой объект класса XML или XMLNode являясь наследником Object имеет доступ ко всем свойствам и методам, заданным в Object.prototype, при условии, что эти свойства или методы не перекрыты их собственными одноименными свойствами или методами.
Используя простой обход Object.prototype, можно увидеть все унаследованные свойства и узнать, действительно ли эти свойства являются унаследованными.
01020304
ASSetPropFlags(Object.prototype, null, 6, 1);
for (i in Object.prototype) {
trace((Object.prototype[i] == XMLNode.prototype[i])+"\t"+i);
}
Результат:
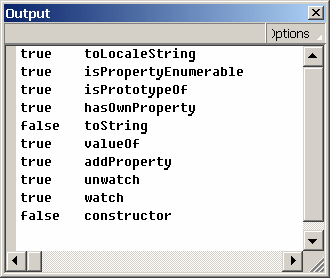
Сравнивая одноименные ссылки в прототипе Object и XMLNode, видим, что только toString и конструктор класса constructor разные, все остальное успешно наследуется.
Object.prototype.toLocaleString()
Метод. Возвращает результат, аналогичный toString. В настоящий момент реализован примерно следующим образом:
010203
Object.prototype.toLocaleString = function () {
return this.toString()
}
Метод не документирован, я думаю, он включен «на будущее» для таких случаев, как, например, преобразование объекта Date в строку, использующую названия месяцев и дней недели на языке пользователя.
Object.prototype.isPropertyEnumerable()
Метод. Возвращает булево значение, характеризующее видимость свойства при обходе объекта циклом for..in.. .
Пример:
010203
trace(Object.prototype.isPropertyEnumerable("toString")) // false
ASSetPropFlags(Object.prototype, "toString", 6, 1)
trace(Object.prototype.isPropertyEnumerable("toString")) // true
Метод не документирован.
Object.prototype.isPrototypeOf()
Метод. Возвращает булево значение, которое показывает, присутствует ли объект prototype какого-либо класса в иерархии классов объекта.
Пример:
01020304050607
my_xml = new XML("<node />")
trace(Object.prototype.isPrototypeOf(my_xml)) // true
trace(Object.prototype.isPrototypeOf(my_xml.firstChild)) // true
trace(XMLNode.prototype.isPrototypeOf(my_xml)) // true
trace(XMLNode.prototype.isPrototypeOf(my_xml.firstChild)) // true
trace(XML.prototype.isPrototypeOf(my_xml)) // true
trace(XML.prototype.isPrototypeOf(my_xml.firstChild)) // false
Из примера видно, что в цепочке наследования my_xml встречаются прототипы классов XML, XMLNode и Object, в то время как my_xml.firstChild не имеет в этой цепочке прототипа класса XML.
Метод не документирован.
Object.prototype.hasOwnProperty()
Метод. Возвращает булево значение, которое показывает, принадлежит ли свойство непосредственно объекту или оно унаследовано от родительских классов.
Пример:
010203040506
XML.prototype.readyForUse = true;
first_xml = new XML();
first_xml.readyForUse = true
trace(first_xml.hasOwnProperty("readyForUse")); // true
second_xml = new XML();
trace(second_xml.hasOwnProperty("readyForUse")); // false
В первом случае свойство задано непосредственно экземпляру, во втором случае это свойство экземпляр наследует из прототипа своего класса и собственного свойства не имеет.
Метод не документирован.
Object.prototype.toString()
Метод. Классы XML и XMLNode его не наследуют, поскольку имеют собственный одноименный метод, описанный выше.
Object.prototype.valueOf()
Метод. Возвращает базовое значение объекта: если такового нет, то сам объект.
0102030405
bla = new String("hello world");
trace(bla == bla.valueOf()); // true
trace(bla === bla.valueOf()); // false
trace(typeof bla); // object
trace(typeof bla.valueOf()); // string
Базовое значение - это всегда значение простого типа: string или number. Все объекты во Flash можно разделить на имеющие и не имеющие базовое значение. Объекты, имеющие базовое значение, используют его для расчетов всех своих остальных свойств.
Например, метод getDay в этом выражении
trace(new Date().getDay())
возвращает не сохраненное ранее значение дня недели, а вычисляет его, основываясь на базовом значении, которое у объекта Date можно получить методом getTime.
Экземпляры классов XML и XMLNode не имеют базового значения, и при вызове ими метода valueOf возвращаться будут вызывающие экземпляры.
Object.prototype.addProperty
Метод. Создает пользовательское вычисляемое свойство. Синтаксис:
my_object.addProperty("property_name", get_function, set_function)
где property_name - строка, имя создаваемого свойства;
get_function - функция, возвращающая значение свойства;
set_function - функция, изменяющая значение свойства.
Этот метод появился в 6й версии Flash и существенно облегчил программирование на ActionScript. В дальнейшем мы будем широко применять создание пользовательских свойств и более подробно изучим их особенности.
Object.prototype.watch, Object.prototype.unwatch
Методы для организации слежения за изменением значения переменных. Object.watch устанавливает слежение, Object.unwatch снимает слежение. В подавляющем большинстве случаев предпочтительнее создавать пользовательские свойства вместо наблюдения за значением переменной.
Object.prototype.constructor
Ссылка на конструктор класса. Классы XML и XMLNode его не наследуют, поскольку имеют собственные. Обратите внимание, что ссылка на constructor выглядит как
test_xml = new XML("<node/>")
trace(test_xml.constructor === test_xml.firstChild.constructor);
Надеюсь, что продолжение следует.
Автор с удовольствием ответит на вопросы, связанные с этой книгой, в рассылке ruFlash.
>>>Read More...